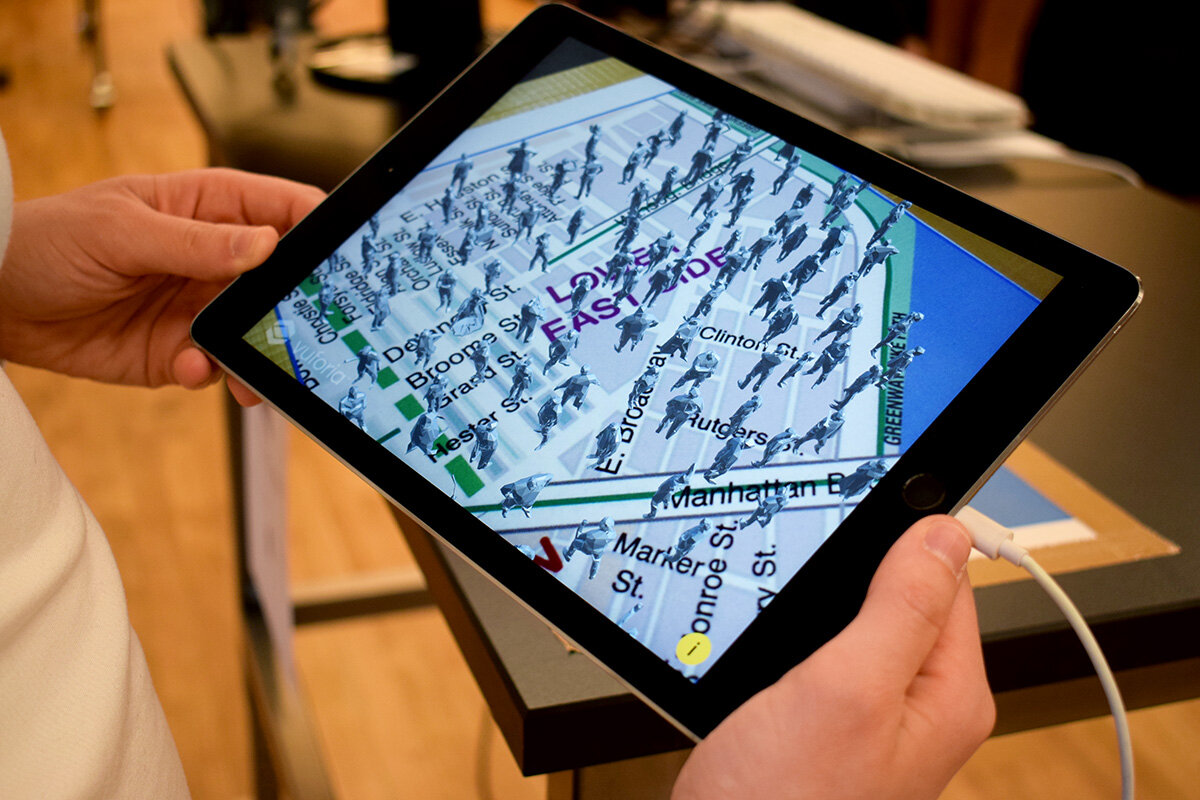
What? 40x (pronounced “Forty Times”) is an augmented reality data art piece that illustrates the lack of affordable housing in the Lower East Side. In NYC, property management companies require renters to have an annual income of 40 times their monthly rent. In certain areas the disparity of rent prices to median household income is incredibly stark, very much so in LES. In this experience, users see 100 figures appear representing the total population of the Lower East Side. Over time the figures disappear leaving a remaining 8% of people to represent those who can actually afford to live in their neighborhood based on the 40x rule. Users can toggle for more information and statistics regarding the data used in this project by touching the screen.
How? This AR experience was designed in Unity and presented in two forms. The first, showcased in the video, acts as an intervention into public space. The mobile device searches for a ground plane so that figures may appear life size on location in the Lower East Side. The second form was a table top demonstration designed for ITP’s public exhibition, the Winter Show 2019. In this version, an image of a LES map spawns the figures.
Why? As New York evolves it is becoming progressively more unaffordable, affecting low income populations the most. With such a large of percentage of rent-burdened New Yorkers, meaning that households spend 30% or more of their incomes on rent, 40x serves to bring light to this issue and start a conversation.
The experience incorporates technical applications of Vuforia, ground plane tracking, image tracking, animation, and UI in Unity.
Created in collaboration with Caroline Neel.
See more about the research and design process:
40x at the ITP Winter Show: